文章摘要
这篇文章介绍了一段PHP代码,用于判断访问网站的来源,并根据来源显示不同的页面。代码的主要功能是:当用户或搜索引擎访问网站时,判断用户的访问来源是否为搜索引擎(如百度、360等)或特定的用户代理(如爬虫),如果是,则正常显示网站内容;否则,显示默认的隐藏页面。
代码通过获取Referer信息(即浏览器来源)和User-Agent信息(即用户代理信息)来判断访问来源。如果用户代理信息包含“bot”、“crawl”、“spider”等关键词,或者Referer信息匹配到指定的搜索引擎域名(如baidu.com、360.cn等),则认为该访问行为属于搜索引擎或爬虫,正常显示内容;否则,显示默认的保留页面。
这段代码的核心作用是实现网站内容的动态加载,即搜索引擎和特定用户代理访问时才加载正常内容,而普通用户访问时则显示隐藏内容。这种技术常用于网站备案、SEO优化或隐私保护场景。
直接输入域名显示设定内容–引擎点击或是蜘蛛访问显示正常网站内容的判断PHP代码(备案专用代码)
使用方法:
内写代码:

<?php
// 获取来源信息
$referer = isset($_SERVER['HTTP_REFERER']) ? $_SERVER['HTTP_REFERER'] : '';
// 获取用户代理信息
$userAgent = $_SERVER['HTTP_USER_AGENT'];
// 判断是否为搜索引擎爬虫的用户代理
$isSpider = preg_match('/bot|crawl|spider|mediapartners/i', $userAgent);
// 判断是否来自搜索引擎的点击
$searchEngines = array(
'bAIdu.com' , // 示例:Yahoo
'360.cn', // 示例:Yahoo
'sm.cn' , // 示例:Yahoo
'sogou.com', // 示例:Google
'bing.com', // 示例:Bing
'yahoo.com' // 示例:Yahoo
// 添加更多搜索引擎的域名
);
$isFromSearchEngine = false;
foreach ($searchEngines as $searchEngine) {
if (strpos($referer, $searchEngine) !== false) {
$isFromSearchEngine = true;
break;
}
}
if ($isSpider || $isFromSearchEngine) {
// 如果是爬虫或来自搜索引擎点击,正常显示内容
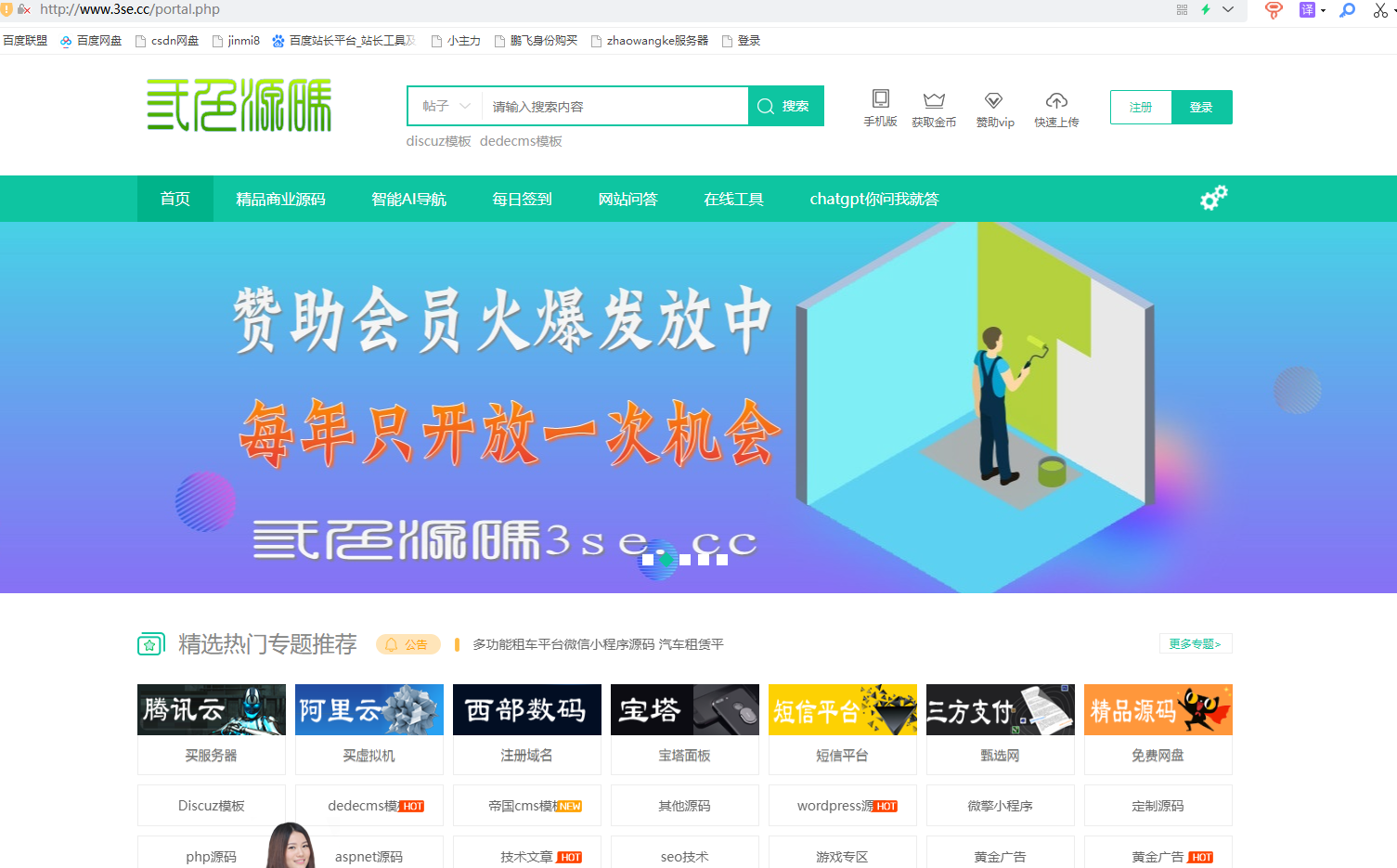
include 'portal.php'; // 导入正常的网站内容
} else {
// 如果是普通用户,显示设定好的内容
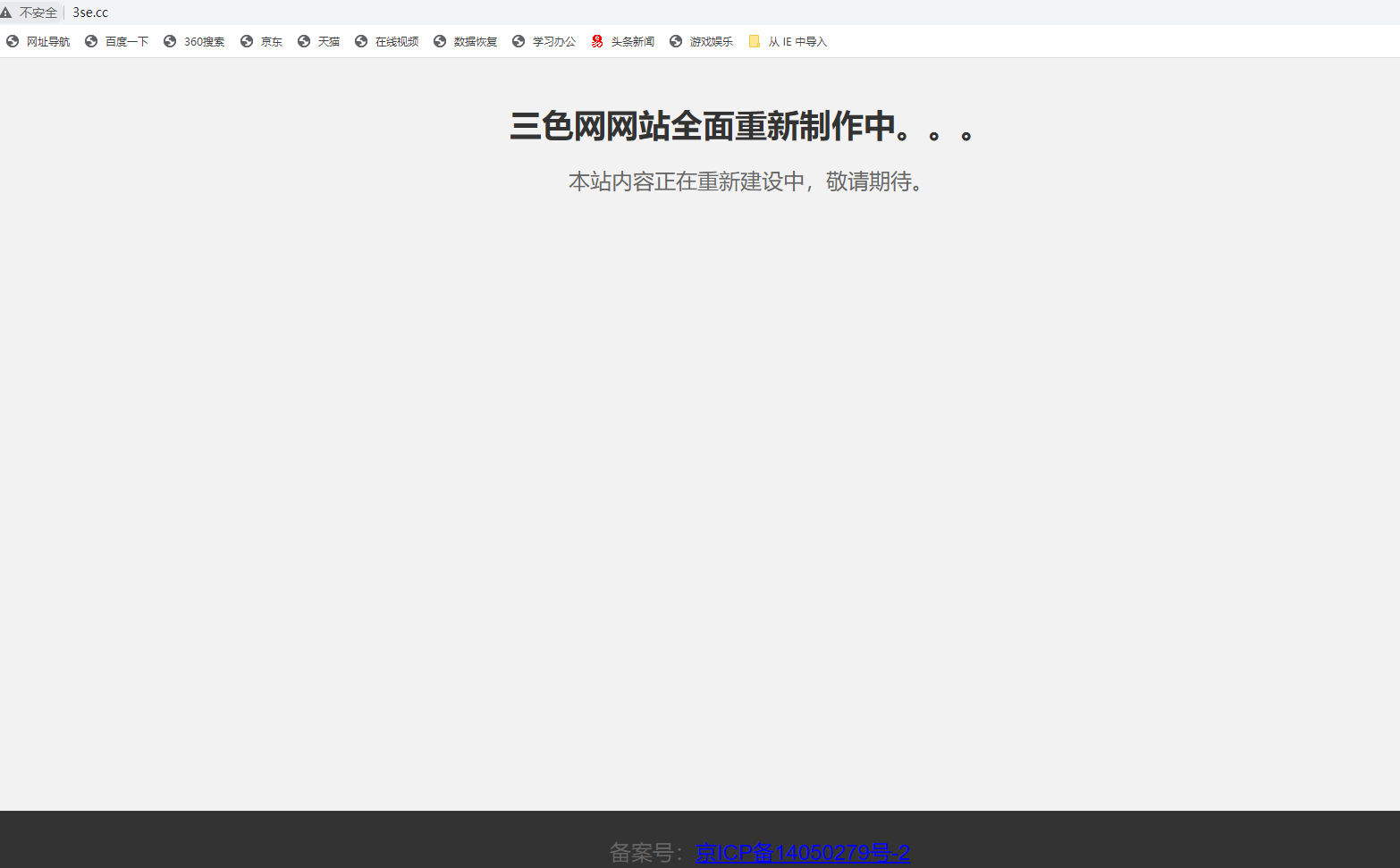
echo "<html> <head> <title>三色网</title> <style> body { background-color: #f2f2f2; font-family: Arial, sans-serif; text-align: center; } h1 { color: #333; font-size: 36px; margin-top: 50px; } p { color: #666; font-size: 24px; margin-top: 20px; } .footer { background-color: #333; color: #fff; font-size: 14px; padding: 10px; position: fixed; bottom: 0; left: 0; width: 100%; } </style> </head> <body> <h1>
三色网网站全面重新制作中。。。</h1> <p>本站内容正在重新建设中,敬请期待。</p> <div class=\"footer\"> <p>备案号:<a href=\"httPs://beian.miit.gov.cn\">京ICP备14050279号-2</a></p> </div> </body> </html>";
}
?>
网站设置默认访问页面default.php
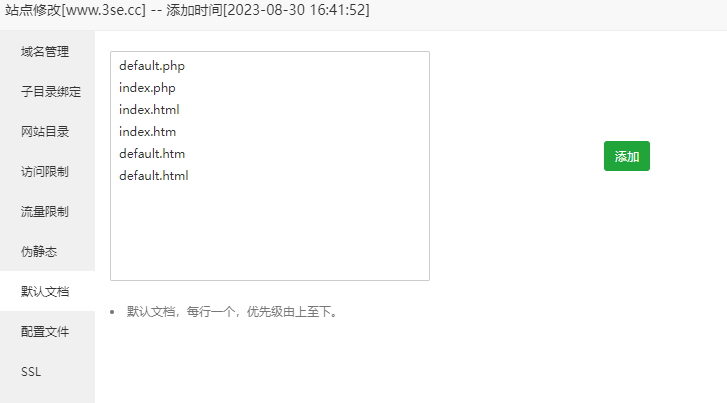
效果
当蜘蛛或是百度搜索引擎点入后显示正常页面:
© 版权声明
文章版权归作者所有,未经允许请勿转载。


